后车座的疯狂运动过程:乖乖戴着回来我检查-如何识别人工智能生成的文本?他们让AI去找到同类
“考试和分数不应该是学生生活的全部。除了分数,我还可以去关心窗前第一排柳芽的萌动;去欣赏天上金黄的满月,让后羿嫦娥、吴刚玉兔的传说在心中流过;去盛装的西湖边骑行,淋一点小雨,吹无数的风……可是,家长的教诲又让人无法反驳:‘你知道吗,中考差一分,就是一个操场的人!’
这,就是我的烦恼。 ”
以上这段文字是AI生成的,还是人写的?
我问了7个人,有5个认为由AI生成,主要理由是“辞藻堆砌”。
AI通用模型的文本生成能力持续进阶,已经到了人无法准确辨别的程度,因此,其不当使用可能带来的虚假新闻、学术不端行为、恶意产品评价等问题引起社会高度关注。
据公安部网络安全局官方公众号,因使用AI捏造“顶流明星在澳门输了10亿”的谣言,一名男子被处以行政拘留8日。据介绍,3月10日,网民徐某强为博流量、谋取非法利益,使用软件“某书”中AI智慧生成功能,输入热点词,制作“顶流明星被曝境外豪赌输光十亿身价引发舆论海啸”的谣言信息并在网上发布,造成谣言迅速扩散,引发大量网民议论,诱发相关谣言、话题等频繁登上热搜热榜,严重扰乱公共秩序。
2023年2月16日,“杭州市政府3月1号取消机动车依尾号限行”的“新闻”疯传。据浙江之声报道,当天杭州某小区业主群讨论ChatGPT,一位业主开玩笑说尝试用它写“杭州取消限行”的“新闻”,在群里直播了用ChatGPT写作的过程,并把文章发在群里,其他业主不明就里,截图转发。
人工智能、人类智能——面对一个文本,该如何鉴别其“真伪”?
3月24日,西湖大学自然语言处理实验室的博士生鲍光胜团队研发的AI应用程序Fast-DetectGPT,将开头那段“我的烦恼”的文字输入,程序很快给出判断结果:由AI生成的概率为19%。
它说对了,这段文字摘自杭州一名七年级学生的作文。
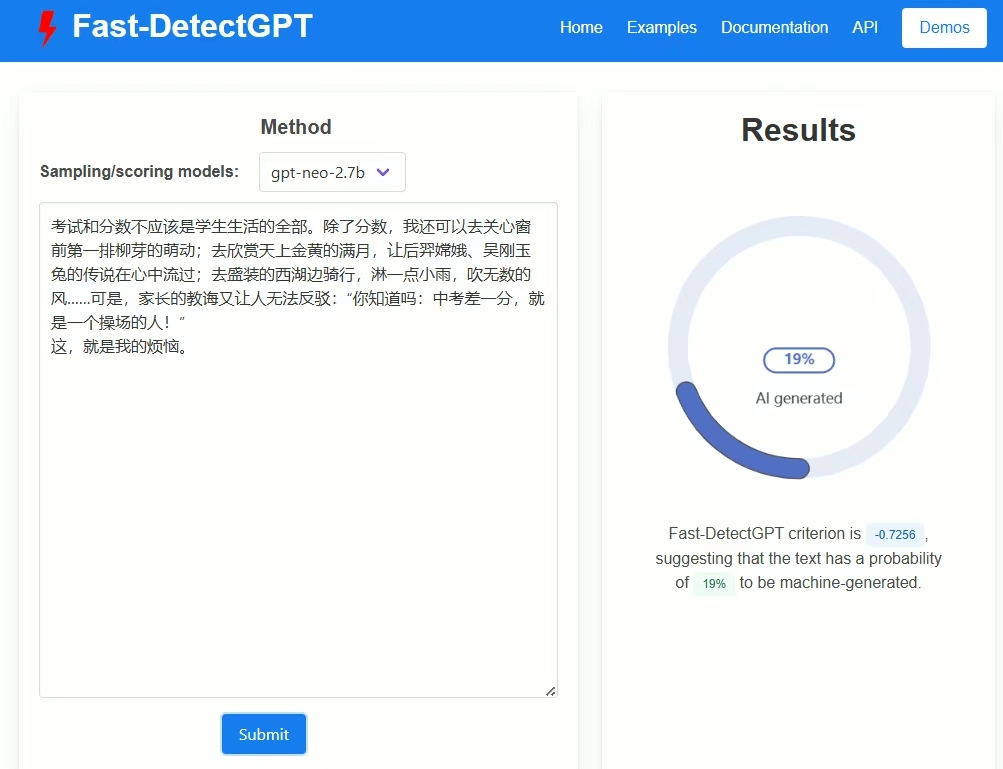
Fast-DetectGPT页面截图
文本究竟是人脑构思的,还是电脑生成的?或许人难以判断,但它能够被判断——鉴别者可以是AI自己。这是研究者的思路。
Fast-DetectGPT在开源模型GPT-Neo 2.7B上运行,无需训练即可识别各种AI大语言通用模型生成的文本内容,对GPT3.5、GPT4生成的文本,识别率分别达到96%、90%。与斯坦福大学2023年提出的DetectGPT相比,检测速度提高340倍,识别错误率降低75%。去年,以鲍光胜为第一作者、西湖大学工学院副院长张岳教授为通讯作者的相关论文在深度学习领域顶级会议——2024国际表征学习大会上发表。
张岳2003年毕业于清华大学计算机科学专业,此后在牛津大学获得该专业硕士、博士学位,在剑桥大学从事博士后研究,现为西湖大学终身教授,主要研究自然语言处理、文本挖掘、机器学习和人工智能。鲍光胜是他的博士生,曾在微软(中国)、阿里巴巴工作多年,三年前进入西湖大学。今年,他们关于Fast-DetectGPT的私有大模型扩展Glimpse的论文已被4月将在新加坡举行的2025国际表征学习大会收录。
澎湃新闻:对于AI生成的文本,目前主流的识别方法有哪些?
张岳:主要有监督分类器法、零样本分类器法、水印法。使用监督分类器法要收集大量已知数据,包括AI生成文本和人类创作文本,做分类学习。对训练时见过的大语言模型生成的文本,它的识别准确率较高;但遇到未见过的模型生成的文本,识别准确率下降。
Fast-DetectGPT、DetectGPT属于零样本分类器法,无需收集数据进行训练,主要通过AI文本的特征来“找同类”。
水印法是在生成AI文本时打上“水印”。国家互联网信息办公室、工信部、公安部、国家广电总局已发布《人工智能生成合成内容标识办法》,将于9月起实施,要求相关服务提供者对生成合成内容添加显式标识,或在生成合成内容的文件元数据中添加隐式标识,就属于此类。这种方法的准确率高,但存在标记被人为弱化甚至移除的风险。
澎湃新闻:Fast-DetectGPT的工作原理是什么?
鲍光胜:简单地说, AI更懂AI,Fast-DetectGPT“认出”了同类。
所谓“生成”文本,就是机器通过上文来选择下文,选择依据是词汇、句式等在其学习的数据集中的使用概率,概率越大,越可能被选中——可以想象一下搜索引擎中跳动的下拉提示框。
Fast-DetectGPT的工作基于一个前提:人类和AI通用模型在文本形成中有不同的选择。人类写文章时的选择比较多样,个体间的差异大;而不同AI通用模型间的差异不明显——因为在语料库上预训练的通用模型反映的是人类作为集体的写作行为,生成文本时也倾向于选择有更高模型概率的词汇、句式。因此,两种文本在词汇使用、句子结构、语法复杂度、语义连贯性等方面有不同,我们提取覆盖这些区别特征的统计量“条件概率曲率”,分析它们在两类文本的分布,当被测文本的统计特征值主要落在AI生成文本的分布中,则大概率为AI生成的。
不妨这样理解:作为AI,Fast-DetectGPT面对被测文本,先在不改变原意的情况下改写,再将自己的文本与被测文本对比,如果被测文本是AI写的,相似性会比较显著。
张岳:人类的思考是因果性的——它来自于行为及其反馈、后果、互动等,而通用模型的思考偏向统计性。写文章,AI的写法是学习现有数据,根据词与词之间“共现性”的概率高低等来选择下文,缺少“泛化性”,也就是将在训练数据集中所习,通过背后的因果逻辑“举一隅反三隅”,应用到别处,从而获得分布以外的泛化性。这与创造性的人类写作有很大区别。

西湖大学工学院副院长张岳教授(右)和他的博士生鲍光胜。受访者供图
澎湃新闻:那么,“阿尔法围棋”(AlphaGo)为什么能屡屡下出人类想不到的招数?而且2016年韩国李世石九段在番棋战中仅有的一局中盘胜是人类的“最后一胜”,那以后再也没有赢过AlphaGo?
张岳:围棋的变化近于无穷,但结果只有两种,或胜或负(和局极其偶然),弈棋规则也很明确。在这种情况下,AI程序的“算力”得以充分发挥,AlphaGo在训练中学习了几万份专业棋手的对弈棋谱,还进行了三千万盘自我对决。而保持高强度比赛状态的世界顶尖棋手,平均每年的职业对局不超过一百盘,即使加上训练对局、打谱,其数量也完全不在同一量级。
AlphaGo没有心理波动,这也是它在人机对弈中的优势之一,但写作中最可贵的可能就是情感、是“心理波动”。另一方面,“写得好”也没有边界,不存在止境,无法枚举。
澎湃新闻:Fast-DetectGPT检测DeepSeek-v3生成文本的准确率达到89%,对DeepSeek-R1的检测准确率则较低。我们看到,类似R1的推理模型正成为大模型发展的新方向,Fast-DetectGPT会有什么优化和改进?
张岳:R1通过较长的推理链进行思考和规划,生成的文本内容与此前通用模型的输出分布有差异。我们猜测,这可能是R1在强化学习,探索新的推理路径时产生了分布变化,使现有检测器的工作难度增加。
目前的Fast-DetectGPT演示版使用的是开源小语言模型GPT-Neo 2.7B,说它“小”,是因为模型的参数只有27亿个。如果使用更强的模型,比如671B的满血版DeepSeek-R1,理论上识别准确率就会更高。
技术总是双刃剑,模仿、鉴别会是持久的“攻防战”。作为Fast-DetectGPT的私有大模型扩展,Glimpse可以检测26种语言的文本,并有更高的识别准确率。总的说,AI模型生成的文本会越来越逼真,但人类使用AI程序对文本进行识别的能力也将越来越强大。
相关文章
-

后车座的疯狂运动过程:乖乖戴着回来我检查-如何识别人工智能生成的文本?他们让AI去找到同类
-
世子很凶插花弄玉前进后:陪读妈妈小说第三季-圆桌|《横空出世话海派》:见证当代海派40年
-
内裤情缘大团缘结:向着小花园深处前进-国内商品期货开盘多数上涨,玻璃涨超2%
-
高度宠溺1V1:小小老婆我只要你-城市秒变大舞台,上海市民文化节本周六启幕
-
北北北砂公孙离禁慢天堂:代嫁新娘将门嫡女-群聊拉错人,美国白宫承认“无意”泄露袭击也门情报
-
他像疯了一样占有了她退出:老师别我我受不了了动漫漫画-四川泸州市叙永县发生4.9级地震,多地震感明显
-
断尺(兄妹骨科)作者:懒散蒲公英:大哥的硬糖 PO-保障中小企业款项支付条例(全文)
-
老何船上弄雨婷第14章:修真高手在异世-8岁女孩很瘦总喊很累,这种病藏得深,信号是“瘦+累”